Snitch (chivato in Spanish, “dedo-duro” in slang Portuguese), if you usually watch CNN, mainly political subjects, that’s a word that you probably hear a lot. The dictionary meaning is: “to secretly tell someone in authority that someone else has done something bad, often in order to cause trouble“. Ok, it sounds too strong maybe for our case, but what we want is a kind of a similar thing: catch (and who caused) the Drifts in Terraform state.
Terraform Drifts
Terraform Drift is when the actual state of your infrastructure is not anymore equals to the state defined by your configuration (Infrastructure-as-Code), then… they differ already.
There are a bunch of tools out there (third-parties, open-source, etc.) that can help with that, as always each one with its own pros and cons (free, expensive, complex, too simple, etc.). Bear in mind that the objective here is not to show a definitive way to handle this, neither a comparison between alternatives, actually this is just an excuse to practice and tune our skills in an AWS event-driven architecture solution.
Hence, the intention here is to build a solution architecture, using AWS resources, to find out about those drifts and take action over them. We can take advantage of one of our event-driven architecture currently implemented (if we have one), or if we don’t have one yet, this is a simple example (and excuse) to start with it.
Event-Driven Architecture at AWS
Events are emitted from services throughout AWS and can be caught using the default Event Bus of AWS EventBridge. It’s even possible to catch events from other services providers (SaaS), as well as create your own custom application Events and Buses. However, in this example, the default Event Bus is enough for our needs.
AWS EventBridge & AWS CloudWatch Events
EventBridge uses the same service API and underlying service infrastructure of AWS CloudWatch Events. As AWS learned with their customers that AWS CloudWatch Events were ideal for building event-driven architectures, they’ve decided to add new features to help build this kind of architecture. But rather than keeping this beneath AWS CloudWatch, they have released those features with a new name, AWS EventBridge, to make clear this expansion compared to CloudWatch Events.
Solution Architecture
Let’s check the architecture that we are going to implement, we will make use of the AWS EventBridge services (default Event Bus) in order to achieve an event-driven architecture:
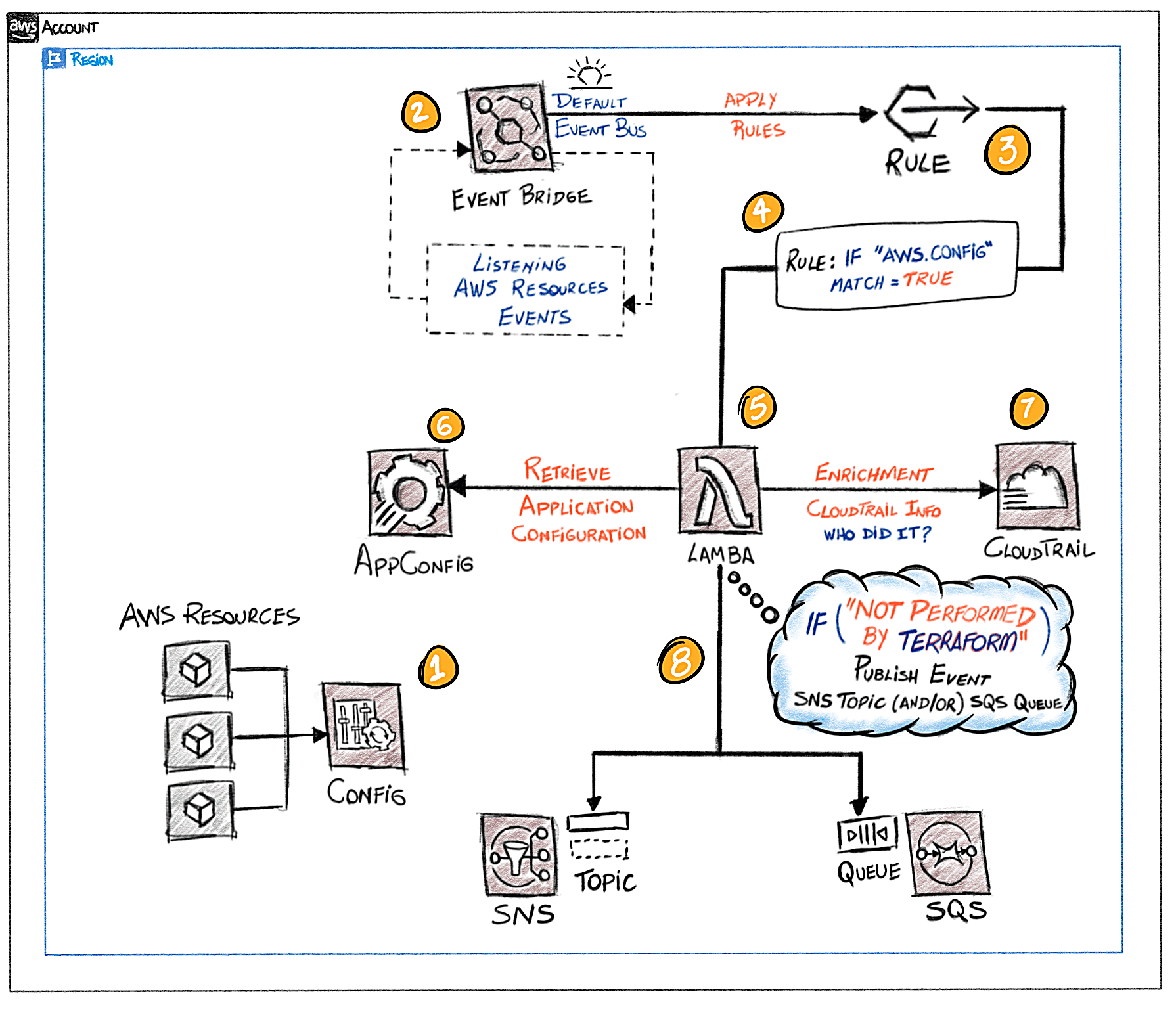
- To capture events of resources configuration changes, we have to enable the AWS Config recorder, this way we can be informed (by an event) when something changed, and if we are interested in this event, do something.
- The AWS EventBridge is going to start to receive events from AWS Config about resources configuration changes.
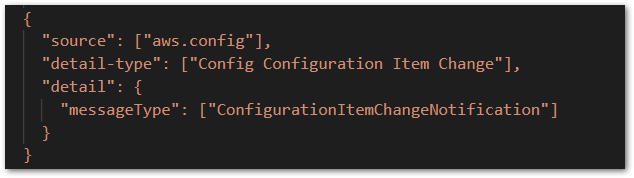
- At AWS EventBridge, we have to create a Rule in the default Event Bus, basically saying which kind of events we want to be caught and handle by this Rule. In our case, events from AWS Config Service of the type Configuration Item Change. That’s the Rule:
- When the event matches the Rule, it means that we found something we are interested in. Then, a target of the Rule will be triggered, in this case, an AWS Lambda Function.
- This is the “heart” of our architecture, where it lays down the decision rule regarding our main objective, that is, answer the question: Was this configuration change made by Terraform or another thing else? and… if the response is a “yes”, send a notification to an SNS Topic.
- Retrieve the Application Configuration for our Lambda function behavior from the AWS AppConfig, like: enable/disable debug messages logging to AWS CloudWatch.
- At this step, we look up the in AWS CloudTrail the Event that is correlated to the AWS Config Configuration Item Change. This way we can find more information about the occurrence event (not only what resource was changed, but who and how did it).
- Finally, if the Configuration Item Change launch by the AWS Config, end up being confirmed by our Lambda function as not performed by Terraform, we send a notification (we snitch) to an SNS Topic (or/and whatever else we want).
In order to come up with a rule that decides if the AWS resource configuration changed was performed by Terraform (step 5), we can use all the information available provided by the AWS Config Event, as well as the correlated AWS CloudTrail Event. In this implementation, we are going to use the information contained in the field userAgent.
You can check all the details, deploy and run this solution using the repository code provided at the end of this article. Let’s deploy and see this solution running.
Deploy and Run!
First, before diving into the code of the main solution, let’s prepared the Terraform “ground” creating an S3 Bucket and a DynamoDB table to remotely save the state and the lockings control.
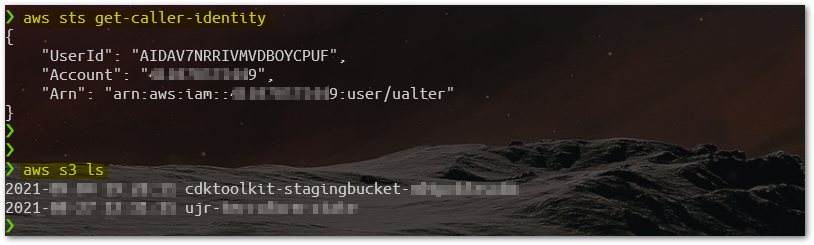
To make things simple, the code is going to use your current AWS connection environment, so make sure that you have the proper AWS Credentials setup, and also that you are pointing to the desired Account. Check that using AWSCLI calling the function get-caller-identity, and/or listing the S3 Buckets, to see if the list is familiar to you.
Change to directory utils/terraform-backend and using the Make automation tool (script already available) launch the target create:
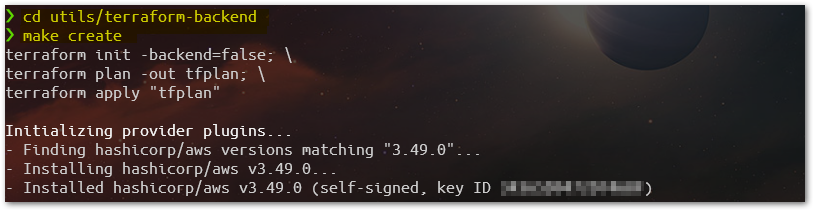
This target will check some dependencies and trigger all the necessary Terraform commands in sequence (check details at utils/terraform-backend/Makefile file). Once we have the Terraform Backend ready, we can proceed and start to deploy our solution.
Go back to the root directory of the project, launch Terraform init command, and then create/select a Terraform workspace called dev. Before starting the deployment, you need to check some parameters in the configuration file for the Terraform dev workspace. There, it needs to be informed of some parameters for the execution context, like the AWS account number, AWS Region, etc. Check the file at workspace-config/dev.yml, and also take a look at the default.yml, for some universal parameters.
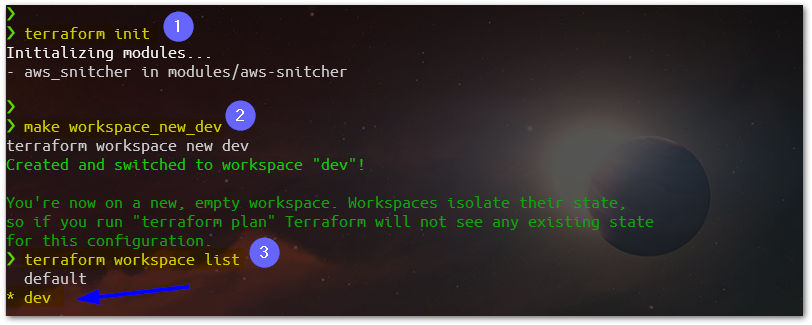
With the dev Terraform workspace selected, using make command we can execute the target called apply.This target will launch the commands terraform plan and apply, consecutively. We should end up with 28 resources added representing the architecture we’ve seen here at the architecture solution diagram.

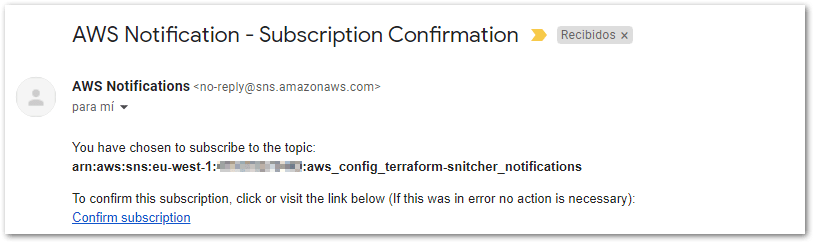
As we mentioned before, about the workspace configuration parameters, at the file workspace-config/dev.yml you can find the value for sns_notification_email. That’s the email that will receive alerts from SNS Topic regarding changes not made by Terraform. A few moments after Terraform finishes the apply command, this e-mail should receive the confirmation subscription, check and confirm the subscription.
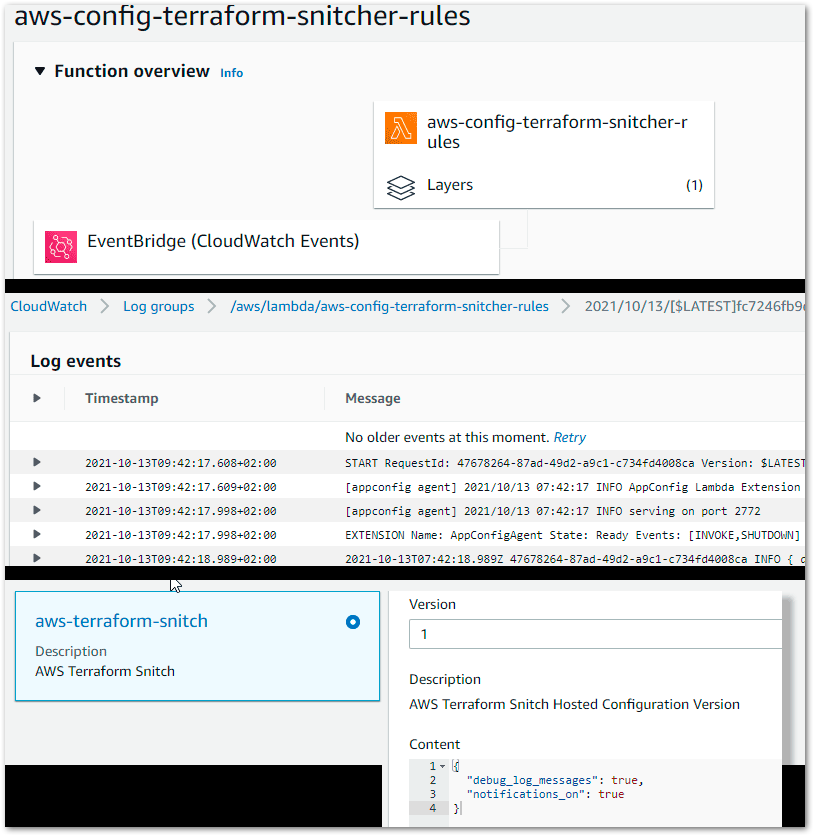
Ok, now we should be ready to test it, we should see all the AWS resources ready, such as our Lambda function having the EventBridge as the trigger, CloudWatch Logs, and our AppConfig configuration.
Testing
Let’s first test if the notification is working, for that using AWS Console, create an S3 Bucket (in this specific test, we named as created-using-aws-console), that should result in an alert and the configured e-mail should receive a notification.

From the AWS Config Event (1) we can see our S3 Bucket name created, from the CloudTrail Event (2) we have the attribute userAgent (3) containing the information about the interface used for this request. As we have set the property notifications_on to true at AWS AppConfig, and this request wasn’t performed by Terraform, a notification to the SNS Topic should be issued (4). And, as result this should happen:

Now let’s prove that we don’t have any notifications when creating some AWS resources using Terraform. For that, at the main root directory, rename the file test_drift_tf to test_drift.tf. This simple Terraform HCL script will only create a new Security Group at the default VPC. Following, execute the command make apply.

We have the AWS Config Event (1) occurred over the default VPC, the CloudTrail Event (2) with the userAgent (3) containing now the information about Terraform being the “agent” behind this request, and according to the rule implemented in Lambda’s function code, this is good, and now, any notification will not be necessary (4).
Conclusion
As mentioned before, there are a lot of tools out there already to take care of Terraform drifts. We only use this subject as an excuse to come up with a solution architecture to show how we take advantage of an Event-Driven Architecture, using AWS resources. Based on this standard, we can have this architecture as a reference model to achieve concrete solution architecture implementations to match and fulfill similar requirements.
Source code: https://github.com/ualter/aws-terraform-snitcher-article

